Machine Learning
[A new world is coming-A new change in malware detection using machine learning]
Introduction
In March 2016, the confrontation between Google's AlphaGo and Lee Sedol was enough to instill fear and possibility about artificial intelligence. A year and a half later, Google surprised the world again with the introduction of the new Alphago Zero. This is because they have won 100 of 100 matches against AlphaGo. What is even more surprising is the learning method of AlphaGoZero. This is because, while AlphaGo in the past repeatedly learned human notation, AlphaGoZero learned by itself based on the rules of Go. Through Reinforcement Learning without human supervision, I realized the basic knowledge of Go, such as understanding the 'axis', and reached a level that greatly exceeded my existing skills. Now, AlphaGo's scalability is drawing attention. This is because it has fully demonstrated the possibility that artificial intelligence and machine learning can be applied to various fields through general-purpose learning, not Go. What if it is applied to the field of information security? Based on this potential, many security companies are already introducing technologies and solutions that apply artificial intelligence and machine learning or are making large investments.

Machine learning is playing a big role in information security. A typical example is the use of malware detection technology to detect and block malicious codes such as APT and ransomware, as well as to prevent threats by detecting anomaly through network and user behavior monitoring.
This document introduces machine learning used by Genian Insights E (Insights) to detect malware. In addition, it aims to increase understanding of new technologies and products such as deep learning.
Understanding Machine Learning
To understand machine learning, it is first necessary to understand the relationship between artificial intelligence, machine learning, and deep learning. The figure below shows the relationship between them.
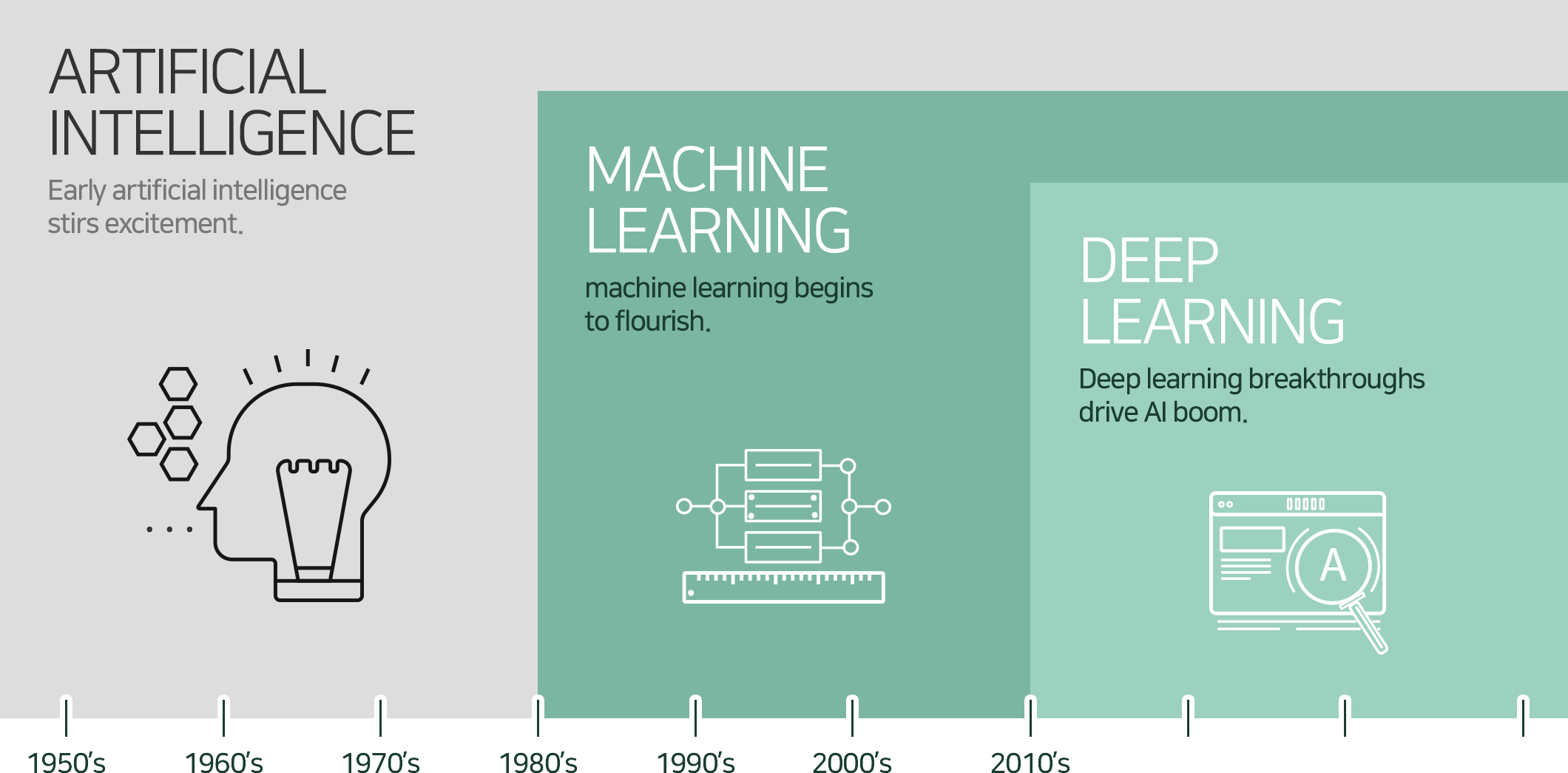
[The relationship between artificial intelligence, machine learning, and deep learning – Nvidia]
Understanding Machine Learning
Artificial intelligence is a concept that emerged a long time ago. At the time, I dreamed of a computer with characteristics similar to human intelligence. In other words, we aimed to develop a general AI that has human thinking ability and thinks like a human. However, facing many difficulties, general AI has not been realized. The current level is a level that can handle certain tasks, such as classifying images or recognizing faces, at a level above humans. It can be said to be a category of Narrow AI.
Machine Learning: Narrow But Concise Artificial Intelligence
Machine learning is a concrete approach to implementing artificial intelligence. Machine learning analyzes data using algorithms, learns through analysis, and makes decisions or predictions based on what has been learned. In other words, it is a method of learning through a large amount of data and algorithms, rather than coding specific directions or guidelines.
Deep Learning: Deep Learning, the best machine learning to date
Deep learning is a branch of machine learning based on artificial neural networks (ANNs). Artificial neural networks also fluctuate, but achieve tremendous development by overcoming technological limitations, development of hardware such as General-Purpose computing on Graphics Processing Units (GPGPU), and mingling with Big Data. After that, it showed overwhelming performance in various machine learning competitions and stood out. Recently, research on deep learning has been actively conducted in the field of image processing and voice recognition.
Learning and application of machine learning
In the past, the learning method of artificial intelligence was a top-down approach that stores human knowledge and infers it. However, we are more often accumulating some knowledge as a learning process through various experiences and data. Machine learning is a bottom-up approach to developing algorithms and techniques that (machines can learn) improve on their own from data based on interactions with the environment as a way to implement learning capabilities through machines.
Machine learning can be divided into ① supervised learning, ② unsupervised learning, and ③ reinforcement learning according to the learning method.
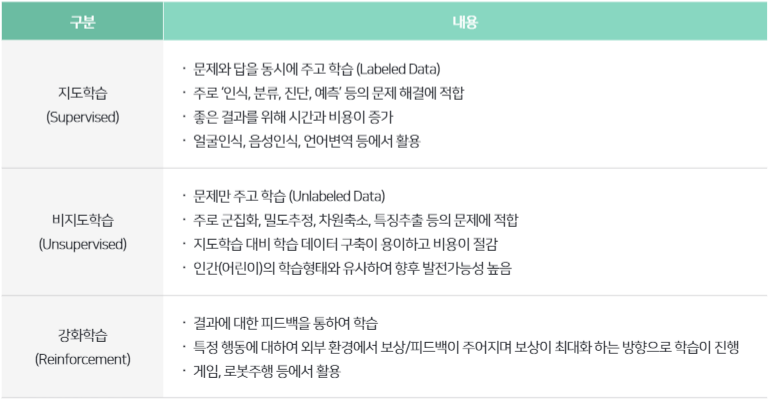
[Comparison of machine learning learning methods]
In the field of information security, research and application of machine learning is being actively carried out. Spam filtering can be said to be the most representative case where supervised learning is applied. In addition, depending on the learning method and characteristics, user behavior analysis (User Behavior Analytics), abnormal behavior detection (Anomaly Detection), malware detection (Malware Detection), authentication (personal identification through behavior analysis), security control, forensic, etc. Research and application are ongoing in a wide range of cybersecurity fields.
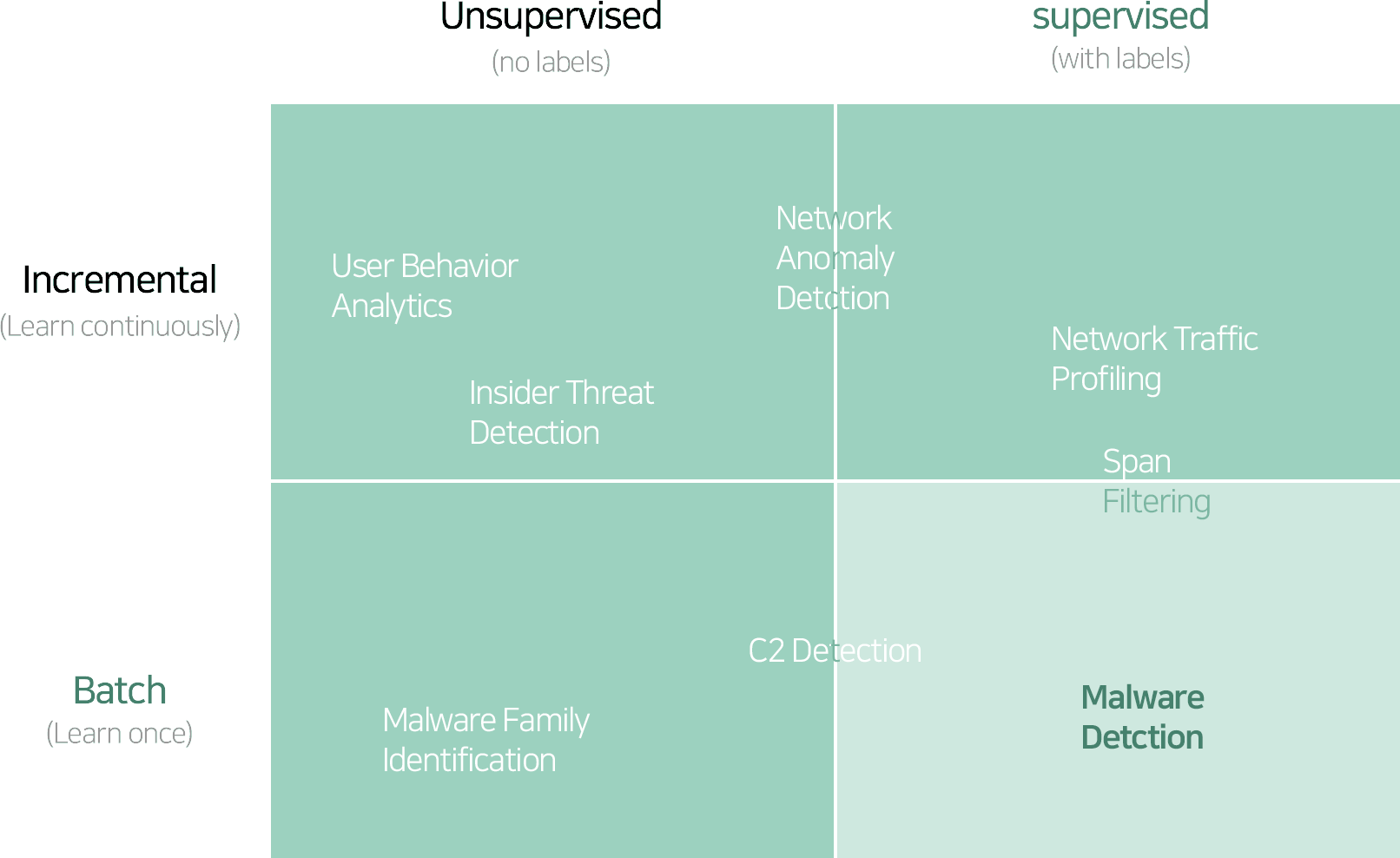
[Utilization of Machine Learning in Information Security Field]
Machine Learning and the Rise of New Players
The use and development of deep learning in the field of malware detection is close to a revolution. Recently, as the number of advanced threats such as APT (Advanced Targeted Attack) and Ransomware has increased exponentially, the Threat Detection & Response capability of the Anti-Virus product line based on the signature is reaching its limit. . With these changes, the introduction of machine learning by traditional security companies such as Symantec is accelerating, and new areas of device security such as Next Generation Endpoint Security (NGES) or Next Generation Anti-Virus (NGAV). Along with that, players are getting attention.

They use machine learning to detect malware and remove threats by detecting abnormal behaviors such as system exploits. In addition, it can analyze network traffic and packets and learn the flow to detect anomaly and prevent threats. It expands the scope of response and enables precise response by analyzing the root cause of detected threats and the correlation between files, processes, and networks. It provides various visualization techniques such as chain events and attack timelines to ensure visibility into threats and timeliness of response.
It is evaluated that it greatly exceeds the functions and utility provided by existing vaccines and device security products. The market evaluation is also positive. The investment and valuation of the company proves this. Although Cylance was founded in 2012, it is valued at a whopping 1 trillion won.
How did these changes become possible in just a few years? Machine learning is at the center of change. In particular, among machine learning, deep learning (deep learning) greatly reduces the effort of programming compared to other machine learning learning methods. In the past, the biggest obstacle to using machine learning was feature engineering. This refers to a series of operations in which an analyst or data scientist extracts features from specific data and reprocesses them. Deep learning is a learning method that automatically extracts and learns these features. Therefore, if a lot of data and computing power are provided, sufficiently reliable results can be expected. In summary, it can be said that the following factors accelerated the emergence of new players along with the development of deep learning.
Reduce data costs
Along with the big data issue, the quantity and quality of data have greatly improved. In the past, only handwritten data (eg, MNIST) was everything, but now you can use tens of millions of high-resolution images (eg, ImageNet), YouTube, and SNS. In particular, in the case of malware such as ransomware, sharing and collaboration are becoming more important with the development of Cyber Threat Intelligence (CTI). As collaboration platforms such as analysis and evaluation of malicious codes such as VirusTotal, malwares.com, and Malc0de expand, the cost of acquiring and reprocessing very high-quality labeled data has increased. decreased, and development became possible based on this.
evolution of hardware
The learning process of machine learning requires enormous computational power. However, the CPU of a general-purpose computer has a limited number of physical cores and is specialized for sequential operations. In comparison, GPUs can have dozens or more cores, and processing them in parallel is very useful for multi-operation, especially for numbers or algorithms. In addition, as a language structure (eg, CuDA) that can use it efficiently was developed and the price became cheaper, deep learning was able to reduce the computing time to several tens. In the past, the 'Google Brain' project, which Google attempted to connect 1,000 general-purpose servers in parallel, can now be processed with three GPU-accelerated servers, and the hardware is developing rapidly.
The evolution of open platforms
Global IT companies such as Google and Microsoft and academic research groups are releasing machine learning-related platforms (frameworks and libraries, etc.) for free. These platforms dramatically lower the technical barriers to entry for users, allowing them to focus on applications and values. In particular, TensorFlow, released by Google, is most commonly used for spam filtering of image mail and image search, and is used in various fields such as malicious code detection and credit card misuse detection using it.
How does deep learning work?
Recently, deep learning has been receiving a lot of attention. A few years ago, machine learning began to attract the general public, and now, deep learning, a type of machine learning, is being talked about as representing machine learning. Companies are risking their lives to secure relevant manpower. Google acquired DeepMind, Facebook appointed Professor Yann LeCun, a master of deep learning, as the head of its AI center, and Baidu, also known as China's Google, also hired Professor Andrew Ng. It looks close to .
So, how does deep learning work?
Let's assume that we are making deep learning that can distinguish polygons and understand how it works conceptually. Which of these is the blue shape on the left?

A person can immediately recognize that the blue object on the left is a square. This is because a person has the knowledge of a concretely abstracted square. So you can immediately determine that the object on the left is a polygon and among them is a square. On the other hand, what about machines, i.e. machines? Unfortunately, it is impossible to store human knowledge and make decisions (judgments) based on it. In the end, it takes the method of recognizing each feature one by one and combining them to make a decision. As a result, the following steps are required.
These features are transferred to deep learning as input data. Deep learning refers to a neural network made up of several layers. A layer is in turn made up of several nodes. In the node, the actual operation takes place, and this operation process is designed to mimic the process that occurs in the neurons that make up the human neural network.
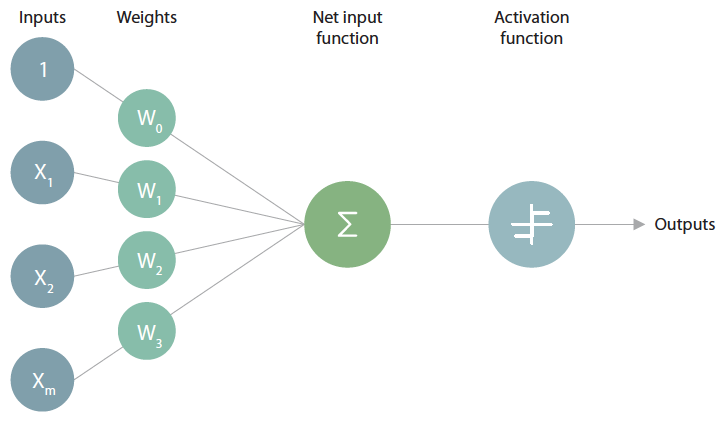
[Operation of nodes – whether active is determined through input data and weights]
When a node receives a stimulus of a certain size or more, it responds, and the magnitude of the response is proportional to the product of the input value and the node's coefficients (or weights). In general, a node takes multiple inputs and has as many coefficients as there are inputs. So, by adjusting this coefficient, you can give different weights to different inputs. Finally, all the multiplied values are added and the sum is input to the Activation Function.
The features mentioned above are the input data of the first layer (Layer 1), and the output (result) of each layer after that becomes the input of the next layer (Layer 2). The more layers the more complex and abstract learning. Weights are fine-tuned during the training process and, as a result, determine which input each node considers important. Ultimately, learning can be said to be the process of optimizing and updating these coefficients so that an optimized result can be derived.
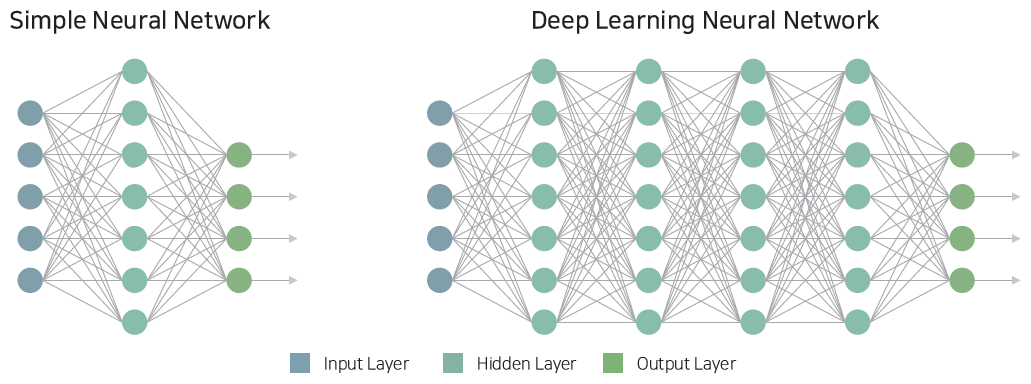
[Simple Neural Network and Deep Neural Network]
After that, it is possible to determine what type of polygon it is by combining all the results. It looks like a decision tree. However, there may be two or more input variables from the previous stage to the next stage, which is a characteristic of the neural network, which is the basis of deep learning.
Deep learning is based on an artificial neural network (ANN), which is a deep neural network (DNN) having a hierarchical structure of an input layer, an output layer, and a plurality of hidden layers. It is a branch of machine learning that is used as a primary method of learning. The actual operation of deep learning can be said to be a repetition of Linear Fitting and Nonlinear Transformation. In other words, it can be said that it is a hierarchical learning method that learns sequentially while building up a simple learning structure.
The biggest feature of deep learning is that extraction and learning of these features for an optimized decision are made together. This greatly reduces the effort of feature engineering described above. Therefore, if a large amount of labeled data is provided, a sufficiently reliable training model can be obtained.
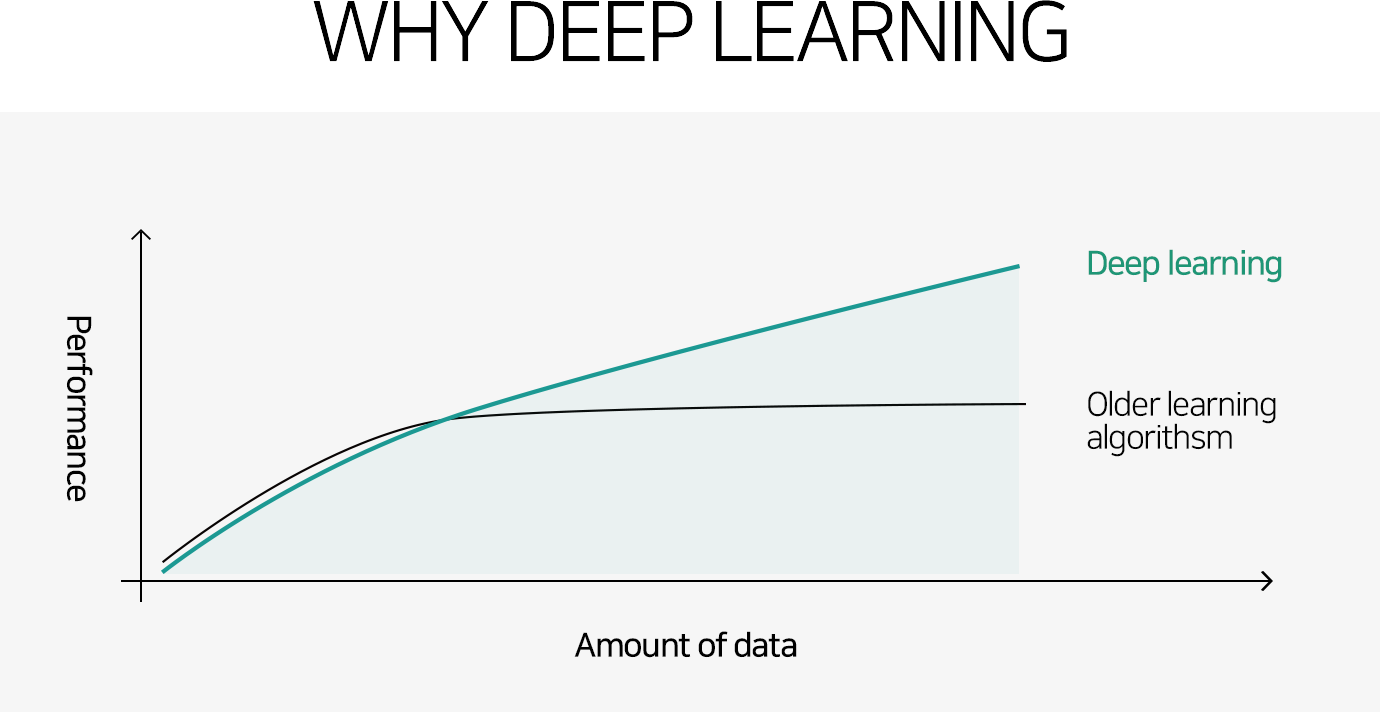
[Why Deep Learning? _ Andrew Ng]
The figure above shows the relationship between the increase in data and the performance of deep learning. This can be said to be the reason why deep learning has received the most attention recently.
Machine Learning and Malware Detection
Recently, ransomware has become a big issue. Ransomware, a type of malware, is used by attackers for financial gain. According to Symantec's Internet Threats Trend Report (ISTR), the number of malicious codes generated in 2015 was about 430 million. The number of malicious codes generated in 2009 was about 2.36 million. In 2015, about 1.18 million malicious codes were generated per day. It can be said that it has increased by 30 times every year.
Variants are among the causes of the rapid increase in malicious code. Most malicious code creators create and distribute variant codes to avoid vaccines. According to German security firm G-Data, In the first quarter of this year, the number of new and variant malware detected reached 1.85 million. New malware appears every 4 seconds, and more than 60% of them are ransomware. Ransomware is spreading rapidly because anyone can easily obtain it and create variants and earn money without being tracked with the advent of virtual currency. The reasons why machine learning is receiving attention in relation to the detection of malicious codes in this environment can be summarized as follows.
Limitations of detection methods
The most basic detection method of Anti-Virus products is comparison with Signature. In 2016 alone, about 1 million new cases of malware were discovered every day. Hundreds of these can be applied to antivirus products. Ultimately, we come to the conclusion that it is impossible to system all malicious codes as signatures.
Limitations of the way it works
Frequent updates are essential to keep signatures up-to-date. Updates over the network are unfortunately not available on closed networks. This is also a big stumbling block for how the cloud works. The recent hacking incident of the Ministry of National Defense can be said to be a representative example of how great results can be caused by an attempt to solve the limitation of such a closed network in a wrong way.
Bypassing security software such as antivirus
An attacker can use the method to detect malicious code in reverse. You can test your own malicious code using VirusTotal or Cuckoo Sandbox, or apply technical methods to bypass it.
For this reason, machine learning is being evaluated as a practical alternative for the detection of an increasing number of malicious codes. Machine learning is a signature It is a technology that detects malicious codes based on non-features. Therefore, there is no relationship between the quantity of malicious code and the detection rate, and it is advantageous for detection of similar variants. So how can machine learning detect malware? It is easy to understand if we think of the deep learning model that recognizes the polygons mentioned earlier. In order to recognize polygons, we talked about three features called 'straight line, connectedness, and angle' and some weights accordingly. The detection of malware is similar. What is important is which feature to use to determine as malicious code and which algorithm to use for learning.
What features can distinguish the executable program from harmful (malware) and normal (normal code)? There are many features available. These include file names and hash values (not useful), header information, calling functions, registry keys, DLLs, and more. Unfortunately, however, there is no single characteristic that can accurately distinguish malware from non-malware. For example, there is a field called SizeOfInitializedData in the header of the executable program. This means the total of the area in which the variables used in the program are initialized. Analysis of the distribution of the features for a number of malicious codes and normal codes is as follows.
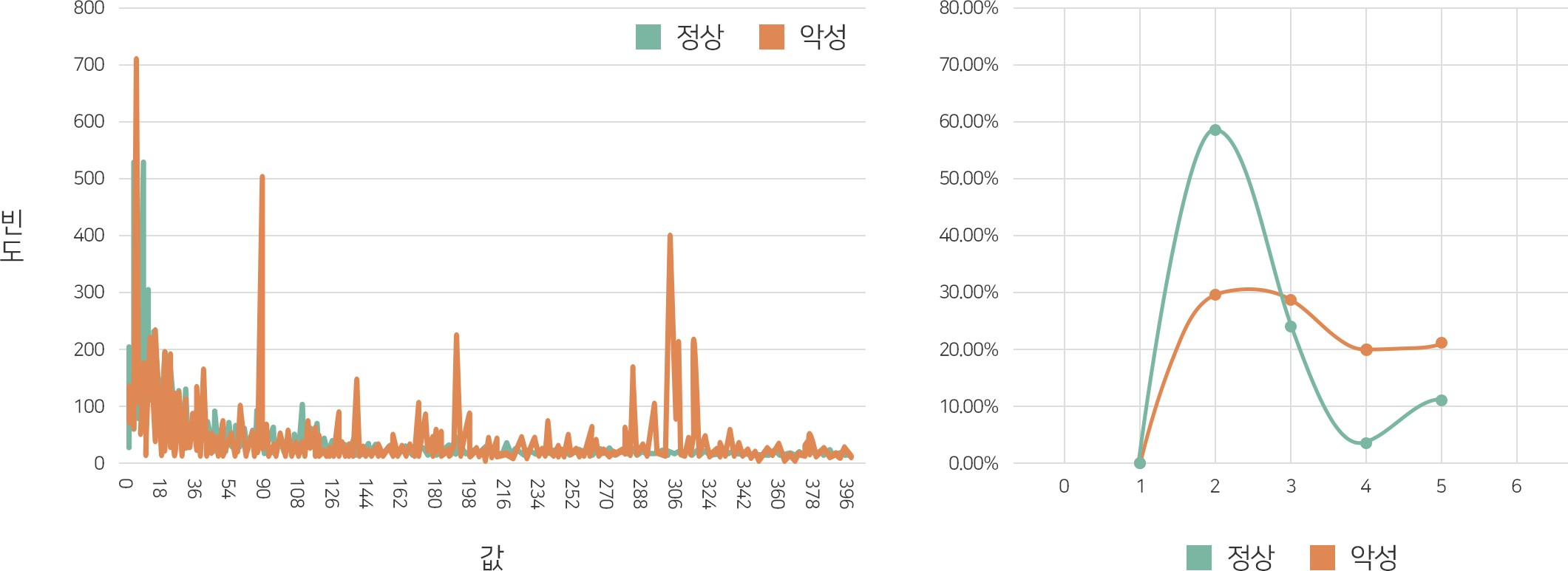
[Distribution of SizeOfInitializedData value according to file size]
A phenomenon in which the distribution is reversed based on '3 sections' occurs. Unfortunately, this feature doesn't seem to be useful. These characteristics are the same and appear repeatedly in most malicious codes and normal codes. Therefore, 'hundreds to thousands' of features and weights are combined and used for actual malware detection. That's why we need machine learning.
In the end, the detection performance depends on which algorithm and how it was trained using which features were extracted/used for malicious programs and normal programs. It is also the reason why various vendors using machine learning can appear. Currently, not only static features but also dynamic features are extracted and used, and various algorithms or ensemble methods that increase prediction performance by using various data together are being used.
Insights E and Machine Learning
Insights E (Insights E, hereafter) of Genius Co., Ltd. is an EDR (Endpoint Detection & Response) solution developed for the first time in Korea as a 'terminal-based intelligent Threats Threat Detection & Response solution'. You can detect advanced threats such as APTs and ransomware and gain visibility into attacks. Through close collaboration with NAC, it is possible to detect and respond to threats at an early stage and minimize the risk caused by threats, which is attracting attention in environments where NAC is already used.
Insights supports multi-step detection methods, including machine learning, to detect advanced threats.
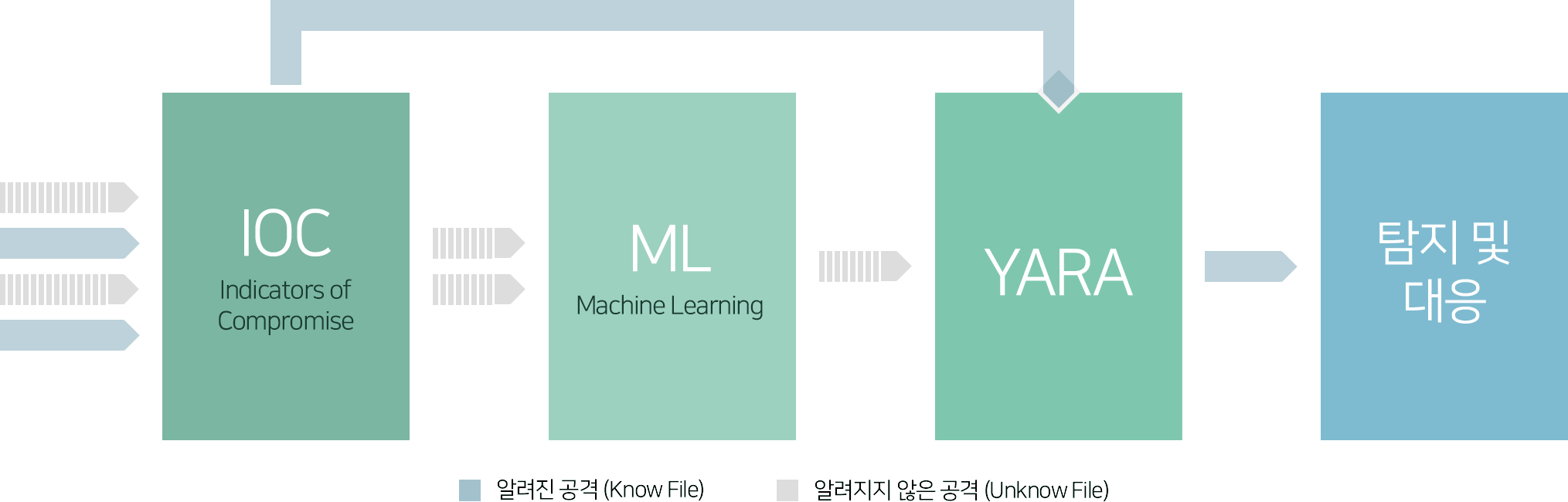
[Insights' Threats Detection Stage]
IOC (Indicators of Compromise)
Malicious code is detected based on related information such as hash, classification, risk, and IP of known malicious code. It is similar to the signature of antivirus products, and many malicious codes are detected in advance at this stage.
Machine Learning (ML)
For executables that are not detected by the IOC, further exploration is done by machine learning. It takes less than a second to extract more than 1,000 features and apply a sophisticatedly trained model. The detection accuracy is more than 99%.
YARA (Yara)
In addition, it detects traces (String) of malicious code inside the executable file based on the rule. It can detect known or unknown pseudo-malware.
Insights uses more than 1,500 features to distinguish between malicious code and normal code, and is researching various learning methods based on deep learning. Among them, based on 4 learning models (Model A, B, C, D), the results of three tests on about 100,000 files are as follows. (The results below are internal measurement results and are derived by validating about 100,000 test sets after training with the training set.)
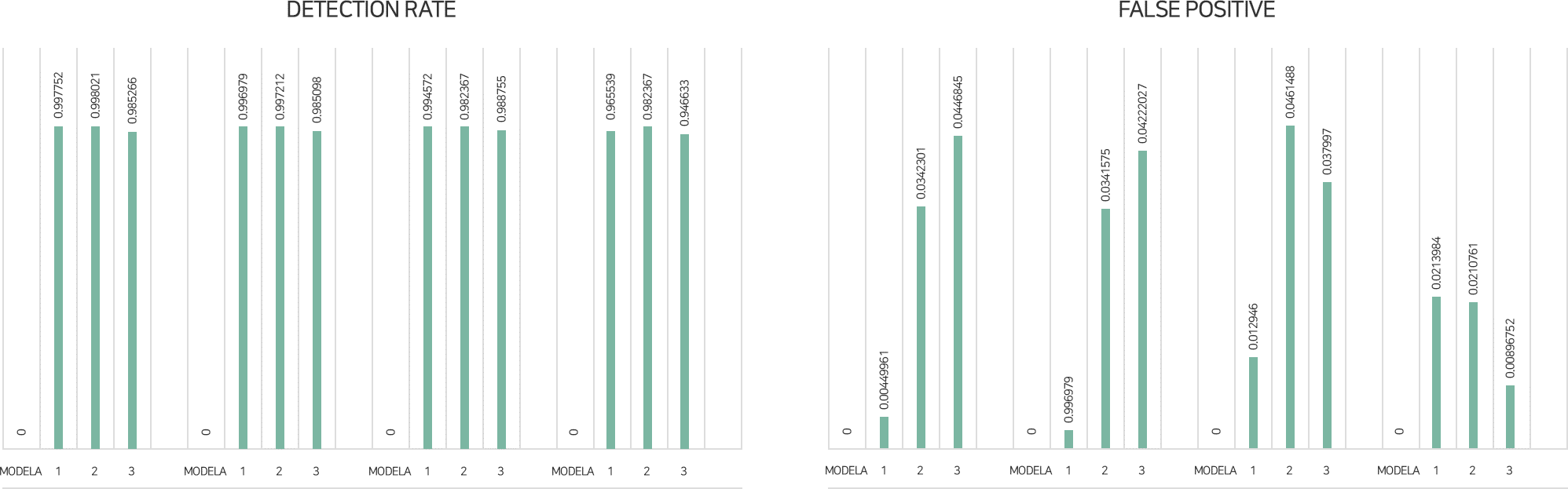
[Result of detection rate (correction, false positive) measured using the test set]
In terms of malware detection rate, the average detection rate of the four models was 98.61%, and Model A, which showed the best result, was 99.36%. In the ratio of detecting normal files as malicious code (False Positive, Type I Error), the average of the four models was 2.6%, and the best Model D was confirmed to be 1.7%. In conclusion, it was confirmed that Model A is the best model in terms of detection rate of malware and Model D is the best model in terms of false positive rate for actual application.
Machine learning applied to real insights is much more complex and sophisticatedly optimized learning models are loaded. As in the previous example, different models are trained and used at the same time, or various methods are applied, such as re-learning judgment results. These efforts are expected to play an epochal role in eliminating security threats caused by actual malicious codes, leading to the advancement of detection rates and reduction of false positives.
[Learning of Neural Network – An optimal model that can distinguish between malicious code and normal code is completed by repeatedly updating the input values and weights of numerous features.]
Is machine learning really all-purpose?
Many companies talk about machine learning. It seems that it is quickly taking its place as an alternative to the increase in malware, particularly the emergence of ransomware and variants. You can even see ransomware being 100% detectable and competing for detection rates. However, in the practical application of machine learning, the following limitations exist. Accurately understanding these characteristics and using them correctly is very important for machine learning applications.
Interpretation of detection results
When a malicious code is detected by machine learning, the result is expressed as a probability (%). That is, the detection result is the same as 'The file called foo.exe is judged to be malicious with a 90% probability'. Specifically, it is not possible to confirm (interpret) whether it was judged as malicious code for any reason. Additional models such as decision tree and linear regression can be used for this interpretation, but this is also close to estimation.
False Positive
More important than the 'high detection rate' is the 'low false positive rate'. In particular, the system of errors (False Positive, Type I Error) that judges normal files as malicious files is very important. A 5% false positive rate seems low in numbers. However, that equates to being able to delete 50 (5%) files when 1,000 files are scanned. Such errors can cause serious damage in practical applications.
Relationship between detection result and response
What action would you take if the file 'abc.dll' was detected as malicious code with a 55% probability? Should I just leave it alone? Or should I delete it? If the system does not boot normally or an application fails after deletion, who is responsible? No matter how excellent machine learning is, it is difficult to link the results to an immediate response. It can be said to be a challenge to a solution consisting of only a single machine learning.
Update
Machine learning also needs an update. The cycle can range from months to years. Threat Detection & Response can be difficult when completely different types of malware appear. Additional learning is required to keep up with the changes in the malware. Therefore, an Eco System that can continuously collect, analyze, and update new malicious codes is required.
[Requires a continuous system for detection rate and false positive rate]
Conclusion
Deep Learning has been studied for a long time. Although there have been ups and downs for a long time, the algorithm has been improved repeatedly as continuous research continues, and it is being evaluated as a machine learning method with the best performance in conjunction with the development of hardware and big data. It is rising with hope.
In particular, the advancement of deep learning in the field of malware detection is phenomenal. However, from the point of view of actual usage, it seems that the dichotomous evaluation of 'fantasy' or 'disappointment' still dominates. Why? This is because there was no accurate understanding and application of the new technology. I think it's because they evaluated the technology simply with distorted and fragmentary metrics such as high detection rates.
A new world is coming. The world has become a world where traditional powerhouses have collapsed in an instant, and new technologies and start-ups can present a new paradigm. Now, an environment where the system and the user are converge and there is no distinction between the network and the endpoints is coming. Information security is also being disrupted by new technologies such as machine learning. But no need to worry. After all, only technology and change for people will survive and expand.